Answering Data Science Interview Question Using Monte Carlo: Batting Average
so I saw this question a while back on twitter:
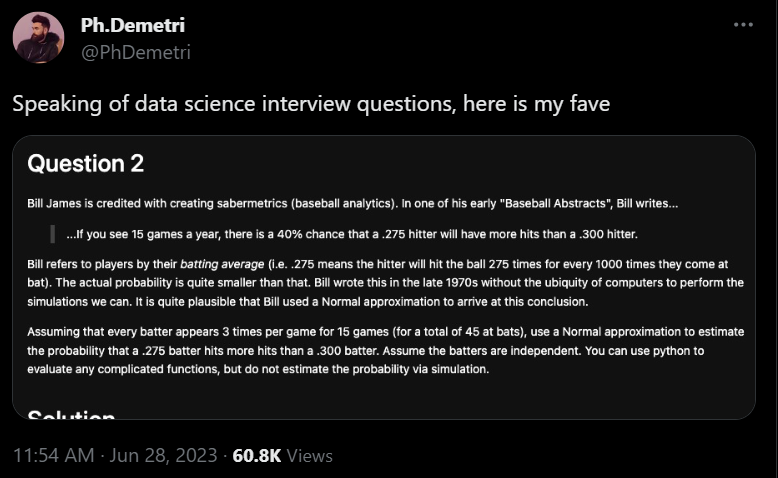
it says not to use a simulation, but we're going to use it because:

frankly I find it easier to think literally than with abstractions
in this day and age with the amount of processing power we have, thinking by approximations isn't obligatory anymore. and in my view the statistical pedagogy hasn't caught up to that, disservicing learners who think better with simulations
some replies from working data scientists make me feel a bit vindicated
we'll be using Julia for its speed relative to Python. we'll also find the closed form solution after using Monte Carlo.
Monte Carlo Solution
since we're using a simulation, we can skip the Normal approximation and calculate using the original distribution, which is Binomial.
we take lots of data points from two Binomial distributions and , subtract the former with the latter to get the difference, then count the probability of getting a positive batting difference.
using Distributions #stats dist. library
n = 10000 #how many times we simulate
function batting_prob_diff(n::Int)
count( i->(i>0),
rand(Binomial(45,0.275), n) - rand(Binomial(45,0.3), n)
) / n
endit's best to display the simulation results cumulatively to see where the probabilites converge.
using Gadfly #chart library
plot(x = 1:n,
y = map((x) -> batting_prob_diff(x), 1:n),
Geom.line,
Guide.xticks(ticks=collect(0:(n/8):n)),
Guide.yticks(ticks=collect(0:0.05:1))
)
we can see from the graph that the result approaches 0.35.
Closed Form Solution
now for the closed form solution. a Binomial distribution can be approximated by a Normal distribution .
so the previous distributions and are approximated by and respectively.
now, lucky for us, the distribution of the difference between two Normal distributions is also a Normal distribution.
so we'll get the resulting distribution's parameters (for Normal it's mean & variance) and calculate the probability.
the new mean is
the new variance is
we can use a cdf function in any programming language to get the solution, or use a cdf table and the z-score if you're using pen & paper (the z-score is ). both approaches will give you a probability of around 0.4.
Hang on a sec...
okay, something's wrong here. our closed form solution gave us 0.4, the same result Bill James got in the 70s. but our Monte Carlo simulation got us 0.35. so which one is correct?
we can start by presuming confidence in our Monte Carlo simulation, as it was a direct calculation, and cast doubt on our closed form solution which relies on approximating the original distribution into another form.
looking around online or in books, it turns out our approximation has a nontrivial issue: we estimated a discrete distribution (Binomial) with a continuous distribution (Normal), so each discrete value in the former is estimated by various values in a continuous interval from the latter.
to correct for this, we can simply subtract 0.5 from our final distribution. so instead of , we're looking for .
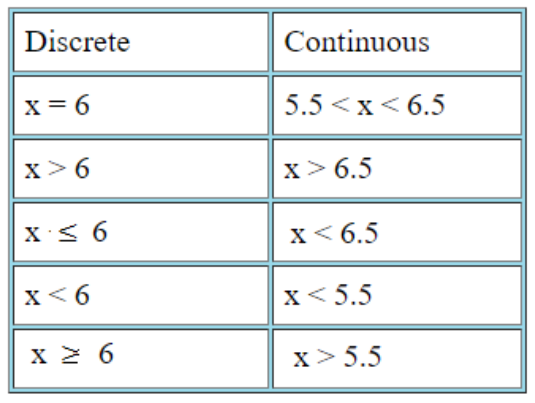
plugging it into cdf functions or a cdf table (with the changed z-score ) gives us 0.35, the same as our Monte Carlo simulation.